SAIDA RL
Welcome to SAIDA RL! This is the open-source platform for anyone who is interested in Starcraft I and reinforcement learning to play and evaluate your model and algorithms.

Table of Contents
What is SAIDA RL?
It is a framework for developing reinforcement learning algorithms with Starcraft I environment.
It includes the simulation environment for Starcraft itself and also tutorials, API document, and various scenarios.
You can develop your own agent and comparing algorithms through challenging and exciting scenarios.
Have fun!
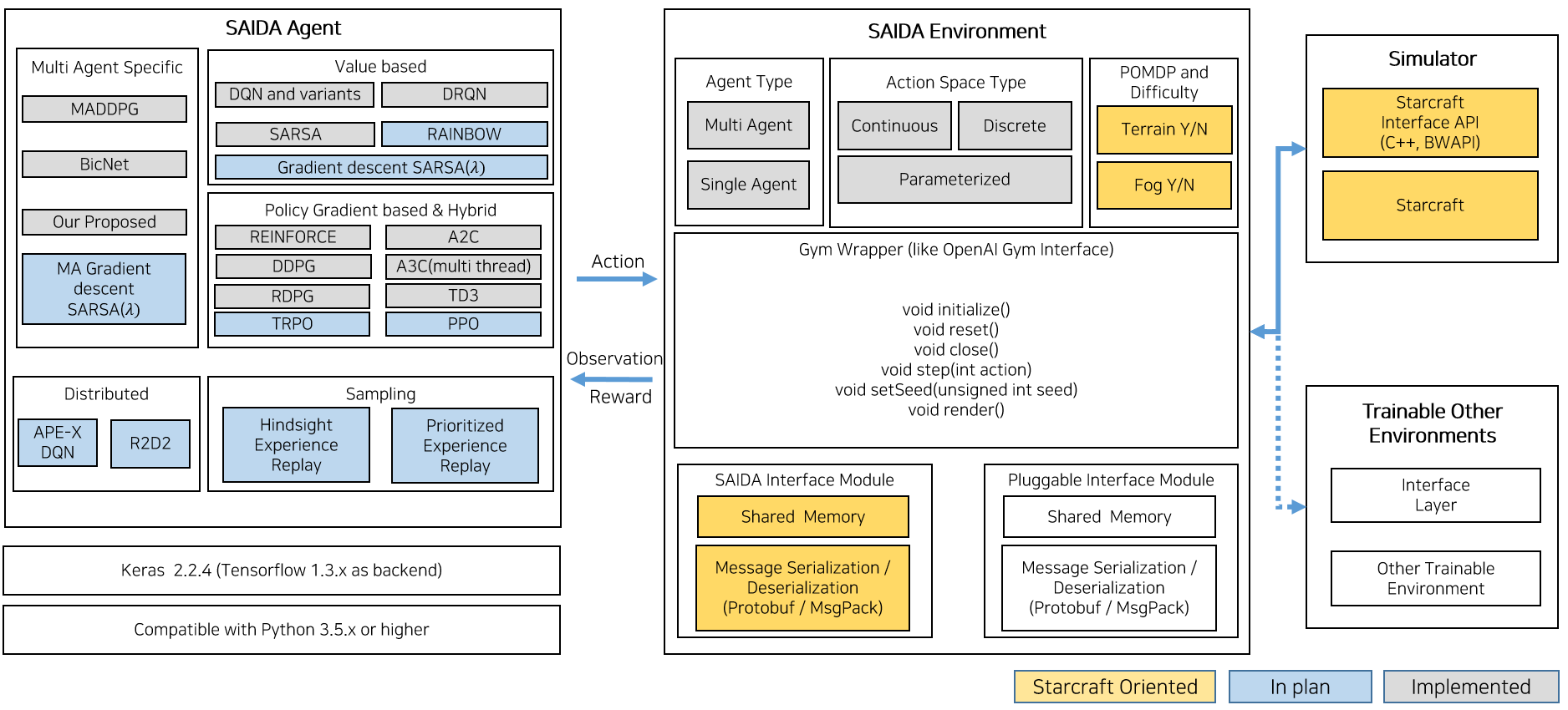
Basics
Anyone who are familiar with reinforcement learning entities and how open ai gym works can skip this. In reinforcement learning, there are the environment and the agent. The agent sends actions to the environment, and the environment replies with observations and rewards.
SAIDA RL inherits interface of Env class of gym and provides baseline algorithms and agent source which is independent from Env. But it is up to you whether to use these baseline sources. The following are the Env methods you should know:
| function | explanation |
|---|---|
| init(self) | Not used. |
| render(self) | Not used. |
| reset(self) | Reset the environment’s state. Returns observation. |
| step(self, action) | Step the environment by one timestep. Returns observation, reward, done, info. |
| close(self) | Close connection with Starcraft. |
Guide
You can access three documentations to run a agent in this environment.
Installation
Tutorials
API
Environment
We built environment based on OpenAI gym. it consists of interface like below.
Agent
Agent we provided is based on keras-rl which is one of top reinforcement learning framework commonly used and we upgraded it by oursevles to support more. But you can use your own agent if you want. We decoupled between agent and environment. there is no dependencies so that, it is compatible with any numerical computation library, such as TensorFlow or Theano. You can use it from Python code, and soon from other languages. If you’re not sure where to start, we recommend beginning with the tutorials on our site.
Scenarios
We have various challenging scenarios for you to motivate trying to solve with reinforcement learning algorithms.
| Map Name | Env Name | Desc. | Terrain(Y/N) | Agent | Action space | Termination Condition |
|---|---|---|---|---|---|---|
| Vul_VS_Zeal_v0 (~3) | VultureVsZealot | Combat scenario between Terran Vulture and Protoss Zealots | It depends on the version of map. | Vulture | Move to specific direction, Patrol to enemy(meaning attack) | Kill or dead |
| Avoid_Observer_v0 | AvoidObserver | Reach the top of map while avoiding observers in the middle area. | N | Scourge | Move to specific direction | Reach the goal or dead |
| Avoid_Reaver_v0 | AvoidReaver | Reach the right-bottom area of the map while avoiding reavers in the middle area. | N | DropShip | Move to specific direction | Reach the goal |
Algorithms
we divided algorithms to three categories.
Value based
Before DQN
-
QLearning
-
SARSA
DQN with variants
Deep Recurrent DQN
- DRQN [11]
Policy based
Multi Agent algorithms
Working Examples
Demos for trained agent’s play
Grid World in Starcraft I
for warming up, you can try this problem by yourselves.

Avoid Observers
Scourge’s goal is to reach top area of current map avoiding collision with Protoss Observers surrounded

Avoid Reavers
Dropship’s goal is to reach bottom area of current map avoiding collision with Protoss Reavers surrounded

Vultures 1 vs Zealot 1
Battle between one vulture and one zealot.
Vultures 1 vs Zealot 2
Battle between one vulture and two zealot.

Plan
- We will update more challenging scenarios soon.
- Multi Agent algorithms
References
- Playing Atari with Deep Reinforcement Learning, Mnih et al., 2013
- Human-level control through deep reinforcement learning, Mnih et al., 2015
- Deep Reinforcement Learning with Double Q-learning, van Hasselt et al., 2015
- Continuous control with deep reinforcement learning, Lillicrap et al., 2015
- Asynchronous Methods for Deep Reinforcement Learning, Mnih et al., 2016
- Continuous Deep Q-Learning with Model-based Acceleration, Gu et al., 2016
- Deep Reinforcement Learning (MLSS lecture notes), Schulman, 2016
- Dueling Network Architectures for Deep Reinforcement Learning, Wang et al., 2016
- Reinforcement learning: An introduction, Sutton and Barto, 2011
- Proximal Policy Optimization Algorithms, Schulman et al., 2017
- Deep Recurrent Q-Learning for Partially Observable MDPs, M. Hausknecht and P. Stone, 2015
- Multi-agent actor-critic for mixed cooperative-competitive environments, Lowe, Ryan, et al., 2017
- Multiagent Bidirectionally-Coordinated Nets Emergence of Human-level Coordination in Learning to Play StarCraft Combat Games, Peng et al., 2017
- Simple Statistical Gradient-Following Algorithms for Connectionist Reinforcement Learning, William et al., 1992